|
HTMLソースを保存する際、適切な文字コードで保存する必要があります。
■ UTF-8の文字コードを指定する
まずはメモ帳の4行目に文字コードを指定します。この指定が無くてもHPは
表示されますが何の文字コードのファイルか判別しやすいため記述します。
HTMLソース
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>HPのタイトル</title>
・
・
・
■ UTF-8でファイルを保存する
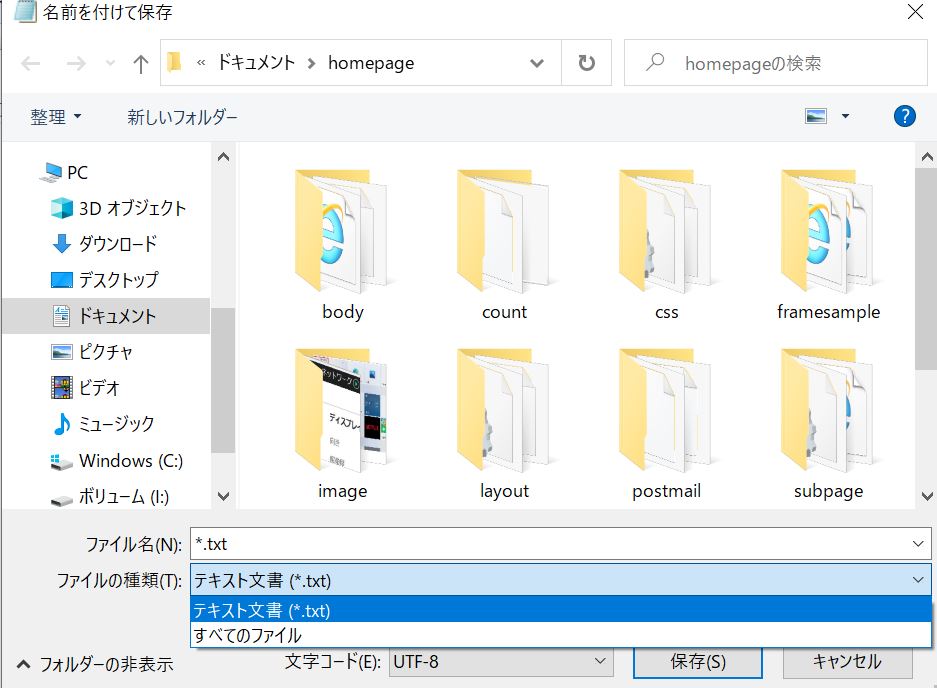
メモ帳の左上から「ファイル」→「名前を付けて保存」を選択します。
するとメモ帳はtxt形式のファイルなのでファイル名の欄には
*.txtと表示されており同様の形式のファイルが一覧に表示されてます。
ファイル名を入力しファイルの種類をテキスト文書で選択し保存すると
テキストファイルとして保存されます。
ファイルの種類を「すべてのファイル」で選択すれば図の例ではドキュメント内の
すべての種類のファイルが表示されます。
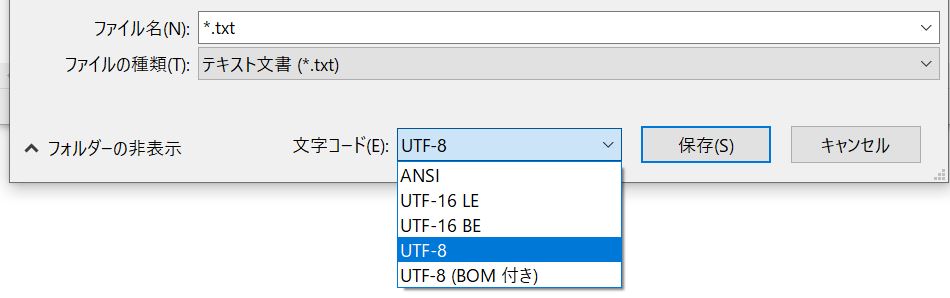
■ 文字コードの種類
文字コードとは文字に番号を割り当てたものです。
世界共通の文字コード規格のことを
Unicode(ユニコード)といいます。
ファイル保存時、文字コードの種類には以下のものがあります。
通常はUTF-8形式を選択し保存します。
| 文字コードの種類 | 説明 |
| ANSI | シフトJISと同じ意味で日本語用の文字コードのこと |
| UTF-16 LE |
LEはリトルエンディアンの略でユニコードの文字を別の形式のデータに変換すること
16進コードで「あ」 という文字は3042でUTF-16 LEではU+4230と前2つ、後ろ2つの数字の順番を入れ替えたデータで表します。
|
| UTF-16 BE |
BEはビッグエンディアンの略でユニコードの文字を別の形式のデータに変換すること
16進コードで「あ」 という文字は0x3042でUTF-16 BEではU+3042とそのままの順番でデータで表します。
|
| UTF-8 |
ユニコード用の符号化方式の1つ。符号化方式とは文字集合(コンピュータ上で表示する文字や数字等の文字の集合)を符号化してコンピュータで使えるようにする変換方式
です。
メモ帳でのHPを作成する際はこの文字コードを選択するのが標準です。
|
| UTF-8(BOM付き) |
BOMとはバイトオーダーマークの略で先頭に0xEF 0xBB 0xBFの三バイトの
データが付いており「このファイルがUTF-8形式である」ことを識別するためのものです。
上のUTF-8は(BOM無し)ということになります。
|
■ 文字化け
メタタグで指定した文字コードと保存時に選択した文字コードが一致しない場合
図のような文字化けが起こるので注意が必要です。
「こんにちは」と表示される筈が左の例はメモ帳でANSIを選択し
保存してますがHTMLソースでUTF-8を指定しているためはてなマークが
表示されてしまっています。
右の例はそれとは逆のパターンでの間違い例で漢字やカタカナに文字化けを起こしてしまっています。
| ANSI (Shift_JIS)で保存 | UTF-8で保存 |
 |  |
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>日記</title>
</head>
<body>
こんにちは
</body>
</html>
|
<!DOCTYPE html>
<html>
<head>
<meta charset="Shift_JIS">
<title>日記</title>
</head>
<body>
こんにちは
</body>
</html>
|
HTMLタグ一覧


|